Note
Go to the end to download the full example code.
How to use sampling_strategy in imbalanced-learn#
This example shows the different usage of the parameter sampling_strategy
for the different family of samplers (i.e. over-sampling, under-sampling. or
cleaning methods).
# Authors: Guillaume Lemaitre <g.lemaitre58@gmail.com>
# License: MIT
print(__doc__)
import seaborn as sns
sns.set_context("poster")
Create an imbalanced dataset#
First, we will create an imbalanced data set from a the iris data set.
from sklearn.datasets import load_iris
from imblearn.datasets import make_imbalance
iris = load_iris(as_frame=True)
sampling_strategy = {0: 10, 1: 20, 2: 47}
X, y = make_imbalance(iris.data, iris.target, sampling_strategy=sampling_strategy)
import matplotlib.pyplot as plt
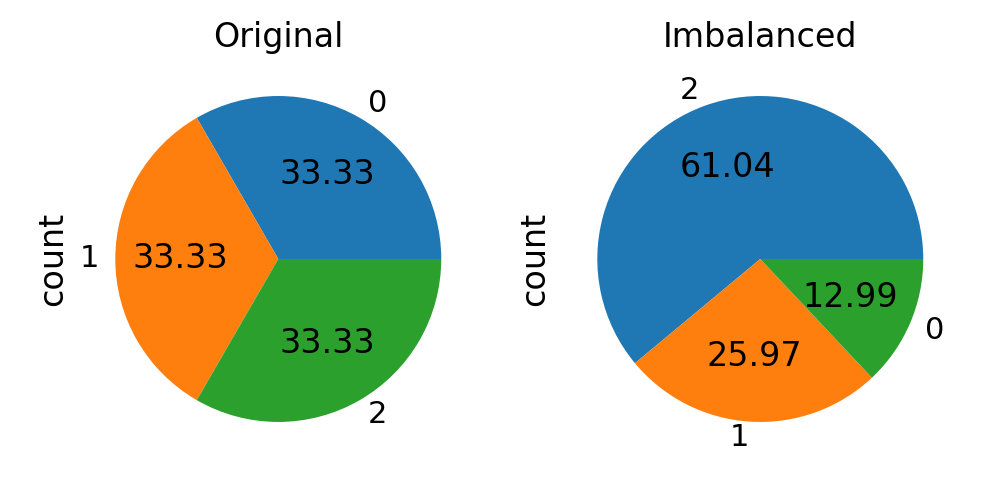
fig, axs = plt.subplots(ncols=2, figsize=(10, 5))
autopct = "%.2f"
iris.target.value_counts().plot.pie(autopct=autopct, ax=axs[0])
axs[0].set_title("Original")
y.value_counts().plot.pie(autopct=autopct, ax=axs[1])
axs[1].set_title("Imbalanced")
fig.tight_layout()
Using sampling_strategy in resampling algorithms#
sampling_strategy as a float#
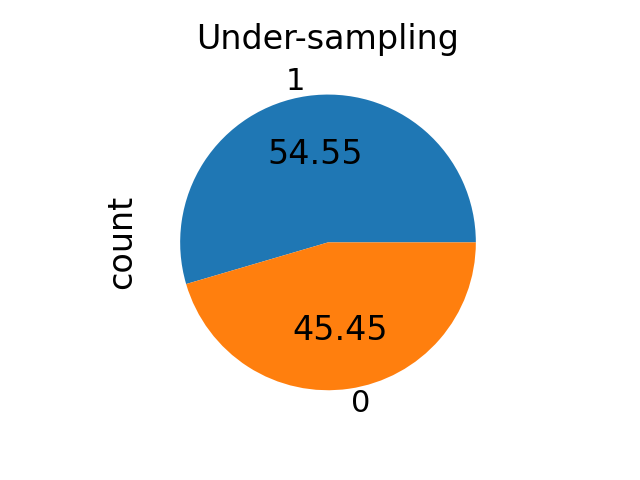
sampling_strategy can be given a float. For under-sampling
methods, it corresponds to the ratio \(\alpha_{us}\) defined by
\(N_{rM} = \alpha_{us} \times N_{m}\) where \(N_{rM}\) and
\(N_{m}\) are the number of samples in the majority class after
resampling and the number of samples in the minority class, respectively.
# select only 2 classes since the ratio make sense in this case
binary_mask = y.isin([0, 1])
binary_y = y[binary_mask]
binary_X = X[binary_mask]
from imblearn.under_sampling import RandomUnderSampler
sampling_strategy = 0.8
rus = RandomUnderSampler(sampling_strategy=sampling_strategy)
X_res, y_res = rus.fit_resample(binary_X, binary_y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Under-sampling")
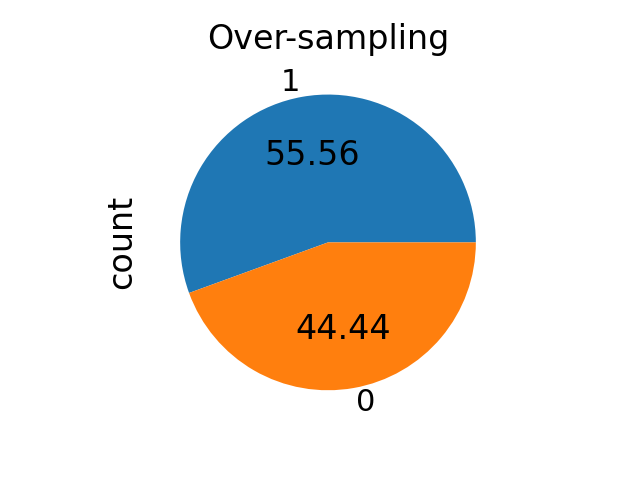
For over-sampling methods, it correspond to the ratio \(\alpha_{os}\) defined by \(N_{rm} = \alpha_{os} \times N_{M}\) where \(N_{rm}\) and \(N_{M}\) are the number of samples in the minority class after resampling and the number of samples in the majority class, respectively.
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(sampling_strategy=sampling_strategy)
X_res, y_res = ros.fit_resample(binary_X, binary_y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Over-sampling")
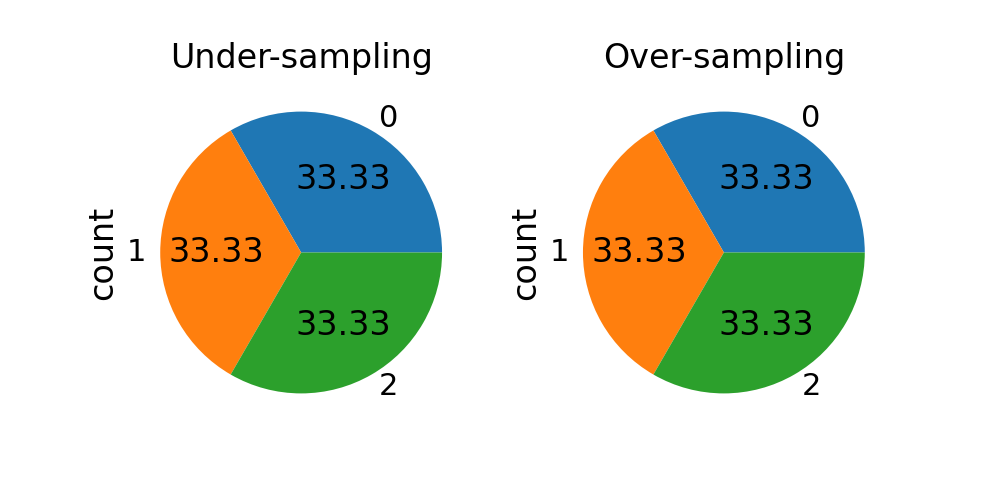
sampling_strategy as a str#
sampling_strategy can be given as a string which specify the class
targeted by the resampling. With under- and over-sampling, the number of
samples will be equalized.
Note that we are using multiple classes from now on.
sampling_strategy = "not minority"
fig, axs = plt.subplots(ncols=2, figsize=(10, 5))
rus = RandomUnderSampler(sampling_strategy=sampling_strategy)
X_res, y_res = rus.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[0])
axs[0].set_title("Under-sampling")
sampling_strategy = "not majority"
ros = RandomOverSampler(sampling_strategy=sampling_strategy)
X_res, y_res = ros.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[1])
_ = axs[1].set_title("Over-sampling")
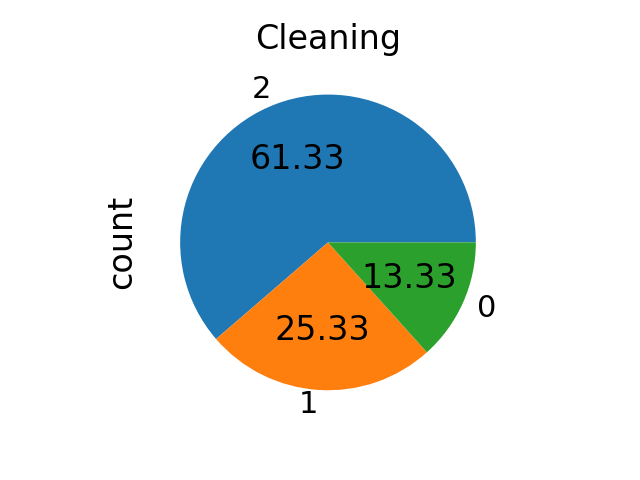
With cleaning method, the number of samples in each class will not be equalized even if targeted.
from imblearn.under_sampling import TomekLinks
sampling_strategy = "not minority"
tl = TomekLinks(sampling_strategy=sampling_strategy)
X_res, y_res = tl.fit_resample(X, y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Cleaning")
sampling_strategy as a dict#
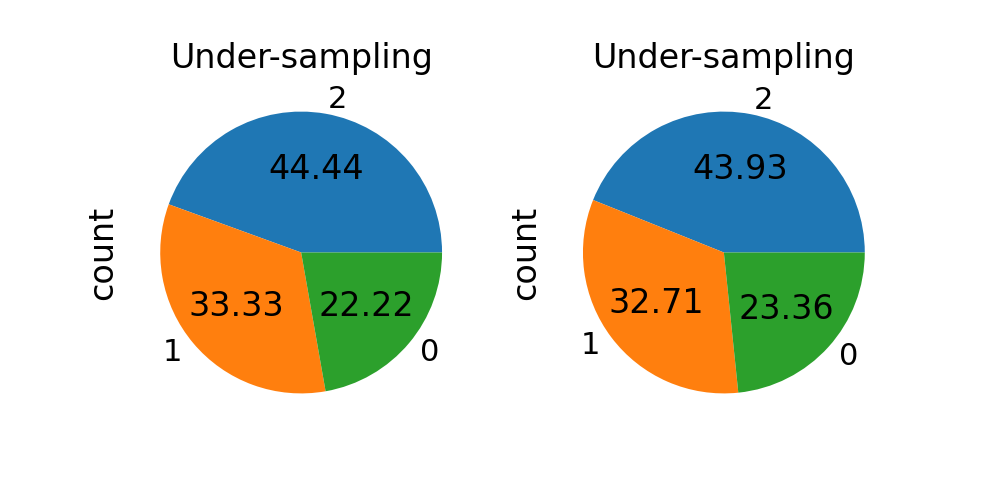
When sampling_strategy is a dict, the keys correspond to the targeted
classes. The values correspond to the desired number of samples for each
targeted class. This is working for both under- and over-sampling
algorithms but not for the cleaning algorithms. Use a list instead.
fig, axs = plt.subplots(ncols=2, figsize=(10, 5))
sampling_strategy = {0: 10, 1: 15, 2: 20}
rus = RandomUnderSampler(sampling_strategy=sampling_strategy)
X_res, y_res = rus.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[0])
axs[0].set_title("Under-sampling")
sampling_strategy = {0: 25, 1: 35, 2: 47}
ros = RandomOverSampler(sampling_strategy=sampling_strategy)
X_res, y_res = ros.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[1])
_ = axs[1].set_title("Under-sampling")
sampling_strategy as a list#
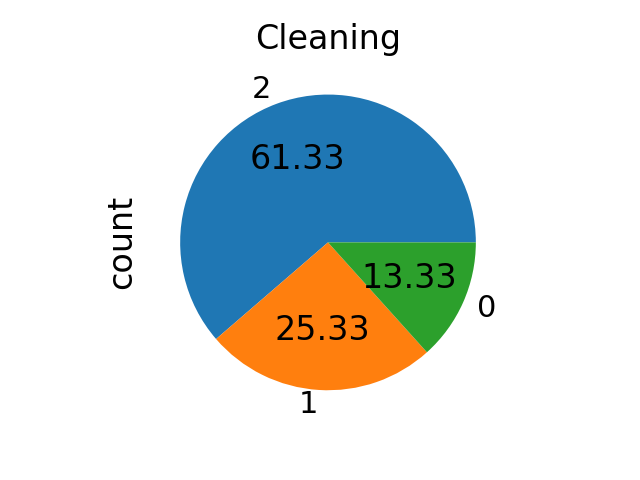
When sampling_strategy is a list, the list contains the targeted
classes. It is used only for cleaning methods and raise an error
otherwise.
sampling_strategy = [0, 1, 2]
tl = TomekLinks(sampling_strategy=sampling_strategy)
X_res, y_res = tl.fit_resample(X, y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Cleaning")
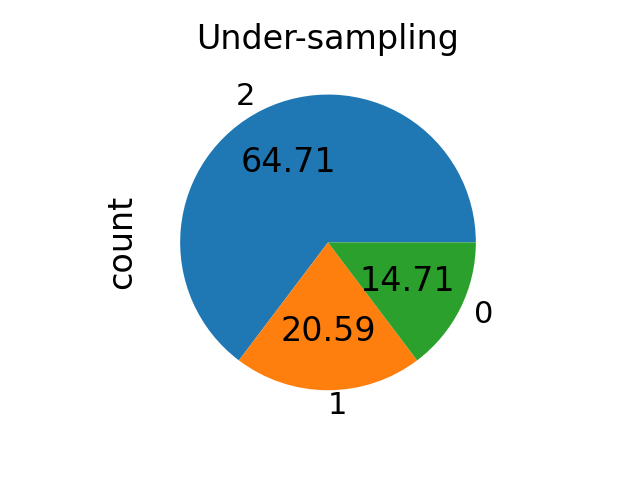
sampling_strategy as a callable#
When callable, function taking y and returns a dict. The keys
correspond to the targeted classes. The values correspond to the desired
number of samples for each class.
def ratio_multiplier(y):
from collections import Counter
multiplier = {1: 0.7, 2: 0.95}
target_stats = Counter(y)
for key, value in target_stats.items():
if key in multiplier:
target_stats[key] = int(value * multiplier[key])
return target_stats
X_res, y_res = RandomUnderSampler(sampling_strategy=ratio_multiplier).fit_resample(X, y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
ax.set_title("Under-sampling")
plt.show()
Total running time of the script: (0 minutes 4.126 seconds)
Estimated memory usage: 232 MB