Note
Go to the end to download the full example code.
Benchmark over-sampling methods in a face recognition task#
In this face recognition example two faces are used from the LFW (Faces in the Wild) dataset. Several implemented over-sampling methods are used in conjunction with a 3NN classifier in order to examine the improvement of the classifier’s output quality by using an over-sampler.
# Authors: Christos Aridas
# Guillaume Lemaitre <g.lemaitre58@gmail.com>
# License: MIT
print(__doc__)
import seaborn as sns
sns.set_context("poster")
Load the dataset#
We will use a dataset containing image from know person where we will build a model to recognize the person on the image. We will make this problem a binary problem by taking picture of only George W. Bush and Bill Clinton.
import numpy as np
from sklearn.datasets import fetch_lfw_people
data = fetch_lfw_people()
george_bush_id = 1871 # Photos of George W. Bush
bill_clinton_id = 531 # Photos of Bill Clinton
classes = [george_bush_id, bill_clinton_id]
classes_name = np.array(["B. Clinton", "G.W. Bush"], dtype=object)
mask_photos = np.isin(data.target, classes)
X, y = data.data[mask_photos], data.target[mask_photos]
y = (y == george_bush_id).astype(np.int8)
y = classes_name[y]
We can check the ratio between the two classes.
import matplotlib.pyplot as plt
import pandas as pd
class_distribution = pd.Series(y).value_counts(normalize=True)
ax = class_distribution.plot.barh()
ax.set_title("Class distribution")
pos_label = class_distribution.idxmin()
plt.tight_layout()
print(f"The positive label considered as the minority class is {pos_label}")
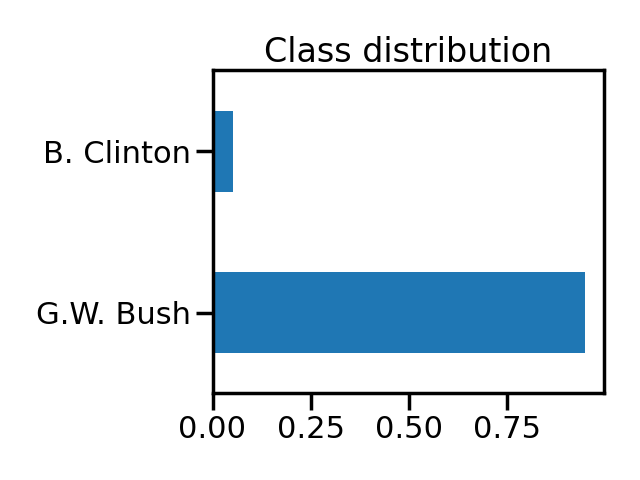
The positive label considered as the minority class is B. Clinton
We see that we have an imbalanced classification problem with ~95% of the data belonging to the class G.W. Bush.
Compare over-sampling approaches#
We will use different over-sampling approaches and use a kNN classifier to check if we can recognize the 2 presidents. The evaluation will be performed through cross-validation and we will plot the mean ROC curve.
We will create different pipelines and evaluate them.
from sklearn.neighbors import KNeighborsClassifier
from imblearn import FunctionSampler
from imblearn.over_sampling import ADASYN, SMOTE, RandomOverSampler
from imblearn.pipeline import make_pipeline
classifier = KNeighborsClassifier(n_neighbors=3)
pipeline = [
make_pipeline(FunctionSampler(), classifier),
make_pipeline(RandomOverSampler(random_state=42), classifier),
make_pipeline(ADASYN(random_state=42), classifier),
make_pipeline(SMOTE(random_state=42), classifier),
]
from sklearn.model_selection import StratifiedKFold
cv = StratifiedKFold(n_splits=3)
We will compute the mean ROC curve for each pipeline using a different splits
provided by the StratifiedKFold
cross-validation.
from sklearn.metrics import RocCurveDisplay, auc, roc_curve
disp = []
for model in pipeline:
# compute the mean fpr/tpr to get the mean ROC curve
mean_tpr, mean_fpr = 0.0, np.linspace(0, 1, 100)
for train, test in cv.split(X, y):
model.fit(X[train], y[train])
y_proba = model.predict_proba(X[test])
pos_label_idx = np.flatnonzero(model.classes_ == pos_label)[0]
fpr, tpr, thresholds = roc_curve(
y[test], y_proba[:, pos_label_idx], pos_label=pos_label
)
mean_tpr += np.interp(mean_fpr, fpr, tpr)
mean_tpr[0] = 0.0
mean_tpr /= cv.get_n_splits(X, y)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
# Create a display that we will reuse to make the aggregated plots for
# all methods
disp.append(
RocCurveDisplay(
fpr=mean_fpr,
tpr=mean_tpr,
roc_auc=mean_auc,
name=f"{model[0].__class__.__name__}",
)
)
In the previous cell, we created the different mean ROC curve and we can plot them on the same plot.
fig, ax = plt.subplots(figsize=(9, 9))
for d in disp:
d.plot(ax=ax, curve_kwargs={"linestyle": "--"})
ax.plot([0, 1], [0, 1], linestyle="--", color="k")
ax.axis("square")
fig.suptitle("Comparison of over-sampling methods \nwith a 3NN classifier")
ax.set_xlim([0, 1])
ax.set_ylim([0, 1])
sns.despine(offset=10, ax=ax)
plt.legend(loc="lower right", fontsize=16)
plt.tight_layout()
plt.show()
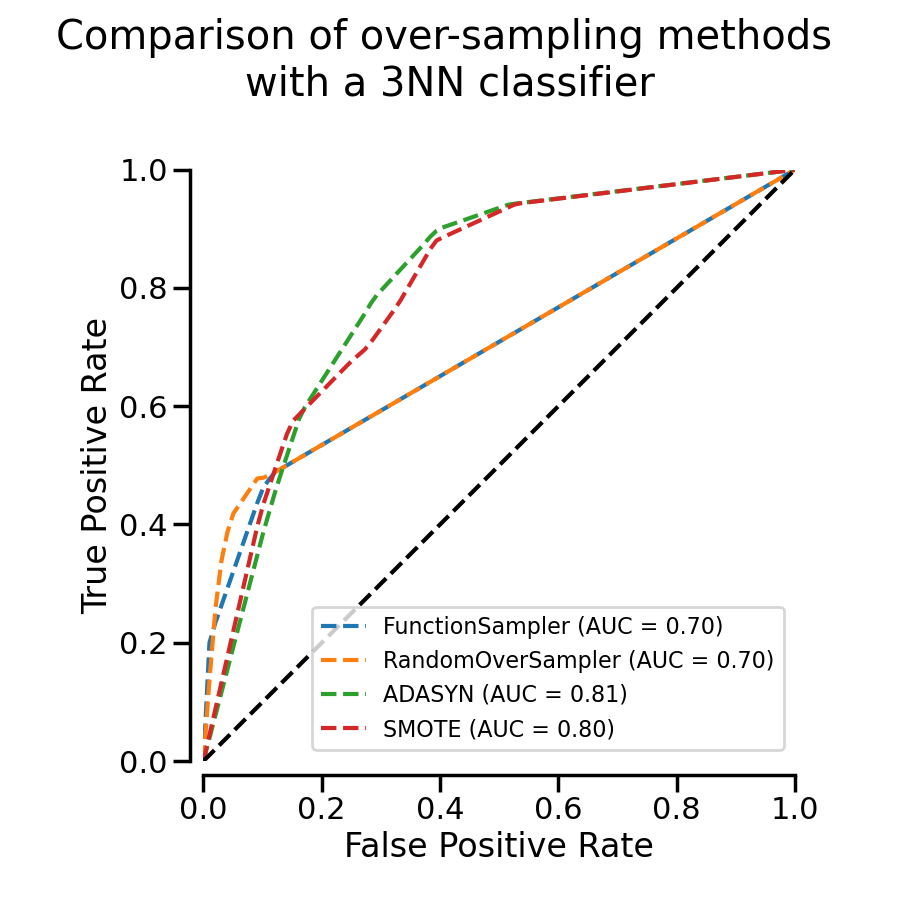
We see that for this task, methods that are generating new samples with some interpolation (i.e. ADASYN and SMOTE) perform better than random over-sampling or no resampling.
Total running time of the script: (0 minutes 45.080 seconds)
Estimated memory usage: 470 MB