make_pipeline#
- imblearn.pipeline.make_pipeline(*steps, memory=None, transform_input=None, verbose=False)[source]#
Construct a Pipeline from the given estimators.
This is a shorthand for the Pipeline constructor; it does not require, and does not permit, naming the estimators. Instead, their names will be set to the lowercase of their types automatically.
- Parameters:
- *stepslist of estimators
A list of estimators.
- memoryNone, str or object with the joblib.Memory interface, default=None
Used to cache the fitted transformers of the pipeline. By default, no caching is performed. If a string is given, it is the path to the caching directory. Enabling caching triggers a clone of the transformers before fitting. Therefore, the transformer instance given to the pipeline cannot be inspected directly. Use the attribute
named_stepsorstepsto inspect estimators within the pipeline. Caching the transformers is advantageous when fitting is time consuming.- transform_inputlist of str, default=None
This enables transforming some input arguments to
fit(other thanX) to be transformed by the steps of the pipeline up to the step which requires them. Requirement is defined via metadata routing. This can be used to pass a validation set through the pipeline for instance.You can only set this if metadata routing is enabled, which you can enable using
sklearn.set_config(enable_metadata_routing=True).Added in version 1.6.
- verbosebool, default=False
If True, the time elapsed while fitting each step will be printed as it is completed.
- Returns:
- pPipeline
Returns an imbalanced-learn
Pipelineinstance that handles samplers.
See also
imblearn.pipeline.PipelineClass for creating a pipeline of transforms with a final estimator.
Examples
>>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.preprocessing import StandardScaler >>> make_pipeline(StandardScaler(), GaussianNB(priors=None)) Pipeline(steps=[('standardscaler', StandardScaler()), ('gaussiannb', GaussianNB())])
Examples using imblearn.pipeline.make_pipeline#


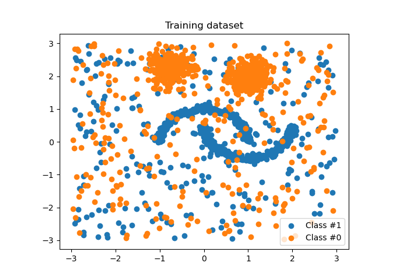
Customized sampler to implement an outlier rejections estimator
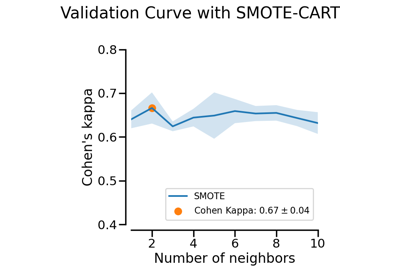
Benchmark over-sampling methods in a face recognition task

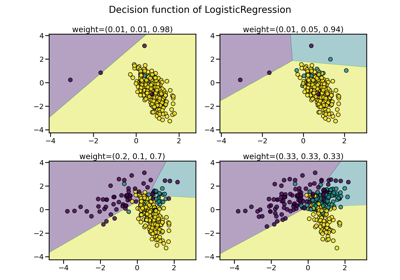
Fitting model on imbalanced datasets and how to fight bias
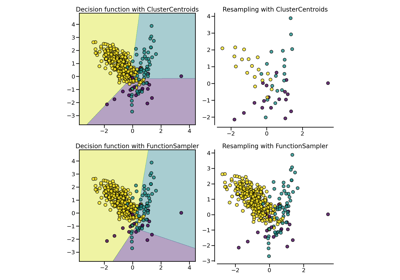
Compare sampler combining over- and under-sampling