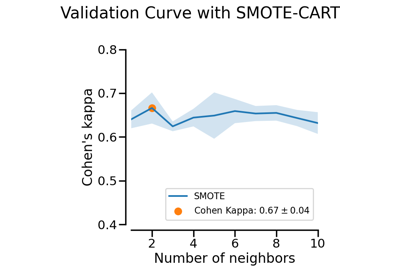
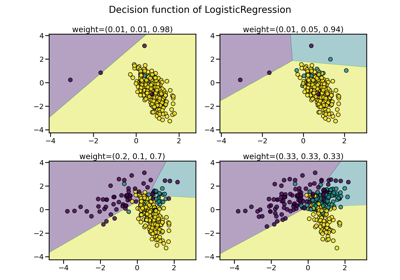
SMOTE#
- class imblearn.over_sampling.SMOTE(*, sampling_strategy='auto', random_state=None, k_neighbors=5)[source]#
Class to perform over-sampling using SMOTE.
This object is an implementation of SMOTE - Synthetic Minority Over-sampling Technique as presented in [1].
Read more in the User Guide.
- Parameters:
- sampling_strategyfloat, str, dict or callable, default=’auto’
Sampling information to resample the data set.
When
float, it corresponds to the desired ratio of the number of samples in the minority class over the number of samples in the majority class after resampling. Therefore, the ratio is expressed as \(\alpha_{os} = N_{rm} / N_{M}\) where \(N_{rm}\) is the number of samples in the minority class after resampling and \(N_{M}\) is the number of samples in the majority class.Warning
floatis only available for binary classification. An error is raised for multi-class classification.When
str, specify the class targeted by the resampling. The number of samples in the different classes will be equalized. Possible choices are:'minority': resample only the minority class;'not minority': resample all classes but the minority class;'not majority': resample all classes but the majority class;'all': resample all classes;'auto': equivalent to'not majority'.When
dict, the keys correspond to the targeted classes. The values correspond to the desired number of samples for each targeted class.When callable, function taking
yand returns adict. The keys correspond to the targeted classes. The values correspond to the desired number of samples for each class.
- random_stateint, RandomState instance, default=None
Control the randomization of the algorithm.
If int,
random_stateis the seed used by the random number generator;If
RandomStateinstance, random_state is the random number generator;If
None, the random number generator is theRandomStateinstance used bynp.random.
- k_neighborsint or object, default=5
The nearest neighbors used to define the neighborhood of samples to use to generate the synthetic samples. You can pass:
an
intcorresponding to the number of neighbors to use. A~sklearn.neighbors.NearestNeighborsinstance will be fitted in this case.an instance of a compatible nearest neighbors algorithm that should implement both methods
kneighborsandkneighbors_graph. For instance, it could correspond to aNearestNeighborsbut could be extended to any compatible class.
- Attributes:
- sampling_strategy_dict
Dictionary containing the information to sample the dataset. The keys corresponds to the class labels from which to sample and the values are the number of samples to sample.
- nn_k_estimator object
Validated k-nearest neighbours created from the
k_neighborsparameter.- n_features_in_int
Number of features in the input dataset.
Added in version 0.9.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during
fit. Defined only whenXhas feature names that are all strings.Added in version 0.10.
See also
SMOTENCOver-sample using SMOTE for continuous and categorical features.
SMOTENOver-sample using the SMOTE variant specifically for categorical features only.
BorderlineSMOTEOver-sample using the borderline-SMOTE variant.
SVMSMOTEOver-sample using the SVM-SMOTE variant.
ADASYNOver-sample using ADASYN.
KMeansSMOTEOver-sample applying a clustering before to oversample using SMOTE.
Notes
See the original papers: [1] for more details.
Supports multi-class resampling. A one-vs.-rest scheme is used as originally proposed in [1].
References
Examples
>>> from collections import Counter >>> from sklearn.datasets import make_classification >>> from imblearn.over_sampling import SMOTE >>> X, y = make_classification(n_classes=2, class_sep=2, ... weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0, ... n_features=20, n_clusters_per_class=1, n_samples=1000, random_state=10) >>> print('Original dataset shape %s' % Counter(y)) Original dataset shape Counter({1: 900, 0: 100}) >>> sm = SMOTE(random_state=42) >>> X_res, y_res = sm.fit_resample(X, y) >>> print('Resampled dataset shape %s' % Counter(y_res)) Resampled dataset shape Counter({0: 900, 1: 900})
Methods
fit(X, y, **params)Check inputs and statistics of the sampler.
fit_resample(X, y, **params)Resample the dataset.
get_feature_names_out([input_features])Get output feature names for transformation.
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
set_params(**params)Set the parameters of this estimator.
- fit(X, y, **params)[source]#
Check inputs and statistics of the sampler.
You should use
fit_resamplein all cases.- Parameters:
- X{array-like, dataframe, sparse matrix} of shape (n_samples, n_features)
Data array.
- yarray-like of shape (n_samples,)
Target array.
- Returns:
- selfobject
Return the instance itself.
- fit_resample(X, y, **params)[source]#
Resample the dataset.
- Parameters:
- X{array-like, dataframe, sparse matrix} of shape (n_samples, n_features)
Matrix containing the data which have to be sampled.
- yarray-like of shape (n_samples,)
Corresponding label for each sample in X.
- Returns:
- X_resampled{array-like, dataframe, sparse matrix} of shape (n_samples_new, n_features)
The array containing the resampled data.
- y_resampledarray-like of shape (n_samples_new,)
The corresponding label of
X_resampled.
- get_feature_names_out(input_features=None)[source]#
Get output feature names for transformation.
- Parameters:
- input_featuresarray-like of str or None, default=None
Input features.
If
input_featuresisNone, thenfeature_names_in_is used as feature names in. Iffeature_names_in_is not defined, then the following input feature names are generated:["x0", "x1", ..., "x(n_features_in_ - 1)"].If
input_featuresis an array-like, theninput_featuresmust matchfeature_names_in_iffeature_names_in_is defined.
- Returns:
- feature_names_outndarray of str objects
Same as input features.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
Examples using imblearn.over_sampling.SMOTE#
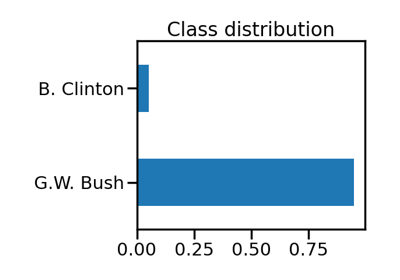
Benchmark over-sampling methods in a face recognition task
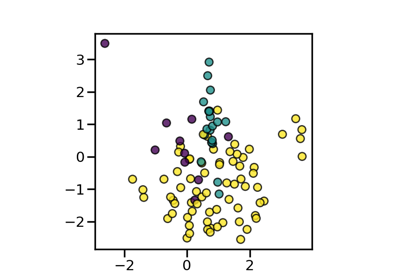
Compare sampler combining over- and under-sampling